Importance of CNN's structure(Automatic Fetal Biometry Estimation)
April 2, 2017
Importance of CNN’s structure
Introduction
요즘 machine learning 연구가 알파고 사태 이후로 곧곧에서 적극적으로 진행되는걸 볼 수 있다. 실제로 충분한 data와 계산할 시간, 컴퓨터의 성능이 따라준다면 상당히 정확한 수준까지 많은 non-linear모델을 근사할 수 있다. 하지만 의료영상 분야에서는 충분한 data를 모으는데 있어서 매우 큰 어려움이 있다.
이러한 어려움을 해결하기 위해선, CNN의 구조 자체를 좀 더 엄밀하게 설정할 필요가 있다. 그 예시로서 이번에 진행한 초음파 영상에서의 태아 복부둘래 길이 측정 자동화 연구이야기를 좀 해볼까 한다.
Fetal Biometry and AC
산모의 건강상의 이유로 CT나 MRI를 촬영하는데에 있어서 제한이 있는 산부인과에서는 태아나 산모의 건강상태나, 태아의 발달상태 등을 확인하기 위하여 초음파영상을 사용한다. 특히 태아의 발달상태, 건강상태등을 체크하기위해서 산모가 산부인과를 갈 때마다 초음파로 측정하는 수치들이 있는데, 이 수치들을 fetal biometry라고 하며, 이중에서도 특히 태아의 머리의 장축 길이(fetal biparietal diameter (BPD)), 머리둘레(head circumference (HC)), 복부 둘레(abdominal circumference (AC)) 등의 수치들은 태아의 발달상태확인과 발달이상의 확인에 중요한 지표로 사용된다. 그런데 이런 수치들을 측정하는 일은 매우 시간이 많이 필요하고 고달픈 일로서 전문가도 한산모당 약 20~30분정도 걸린다고 한다. 매번 해야하는 단순 반복작업이지만, 직업병이 생길적으로 고달픈 일로서, 이번 우리의 연구주제는 이 단순반복작업을 기계가 대신해줄 수 있도록 하여, 의사들의 고충을 덜어주는것이 목표였다.
특히 이중에서도 복부둘레측정의 경우, 다른 수치측정들은 뼈를 발견하여 측정하는데에 반해, 초음파상 밝기 차이가 뼈에 비해서 상대적으로 덜 나는 복부 둘레를 발견하여 둘레를 측정하여야 하기에, 기존 gradient base 방법으론 잘 안되는 경향이 강했다. 그래서 일단 우리는 이 AC의 측정부터 한번 machine learning 기법으로 해보기로 하였다.
여기서 복부둘레란(AC) 두 갈비뼈가 보이고, 태아의 위가 보이며, 제대정맥이 태아의 위(stomach)를 향해서으로 볼록하게 굽어있으며, 제대정맥이 피부까지 이어지지 않은 상태 기준으로 측정한 둘레를 이야기한다.
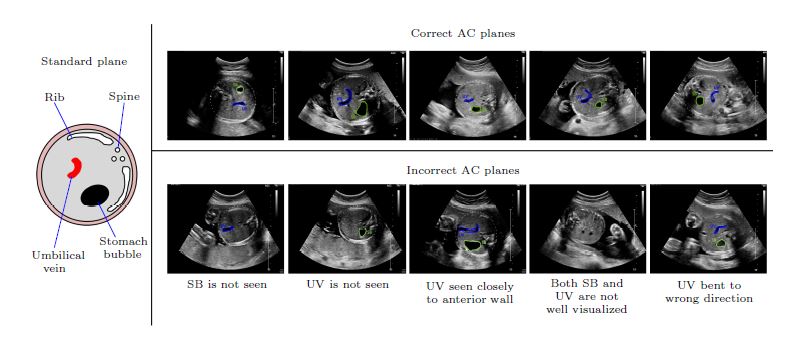
Method
Overall
일단 먼저 우리의 알고리즘 구조부터 설명해보도록 하겠다.
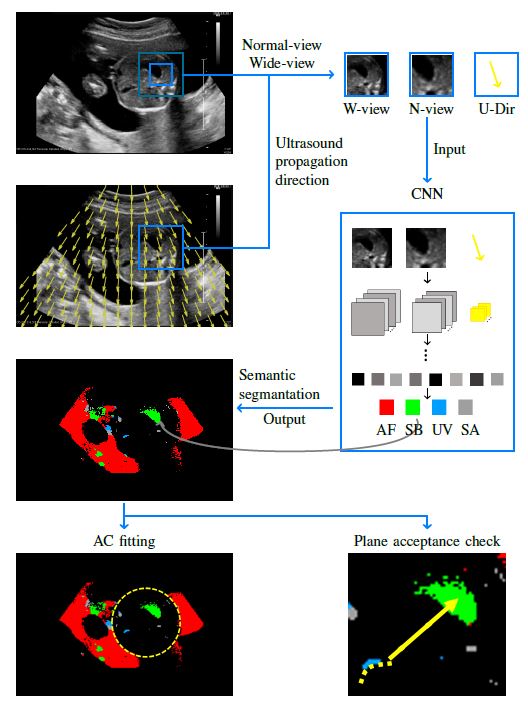
일단 우리는 특정한 ‘검은 점’ 하나를 기준으로 그 주변 국지적 패턴을 파악하는 normal-view 크기의 이미지와, 좀 더 넓은 범위를 확인하는 normal-view 크기의 이미지, 그리고 각각의 점에서의 초음파 진행방향 input data로서 CNN에 넣어 그 ‘검은 점’이 양수인지(Amniotic Fluid(AF)), 태아의 위인지(Stomach Bubble(SB)), 제대 정맥인지(Umbrical Vein(UV)) 아니면 Shadowing Artifacts인지(SA)를 구별하는 구조를 하고 있다.
일단 우리가 ‘검은 점’에 대해서 이러한 구별을 하려고 한 이유는, AF를 명확하게 SA와 구별하여 측정하면 AC가 측정 가능하다고 보았고, 또한 SB, UV를 측정함으로서 AC를 측정하는 사진의 타당성을 판단할 수 있다고 보았기 때문이다.
실제로 그래서 그렇게 구분된 이미지를 이용해 우리는 AC를 측정하거나, 각 초음파 사진이 AC측정에 적절한지를 추가로 판단하였다.
여기서 이번 포스트에선 변형된 CNN이 적용된 저 AF, SB, UV, SA를 구분하는 CNN Structure에 대해 이야기해보도록 하겠다.
Our CNN & Its Explanations
우리는 최초에는 단순구조로 128 by 128 image를(normal view size) input으로 하여 구분하려고 해보았으나, 잘 안되었다. 그리고 분석해본 결과 다음과 같은 사실을 알 수 있었다.
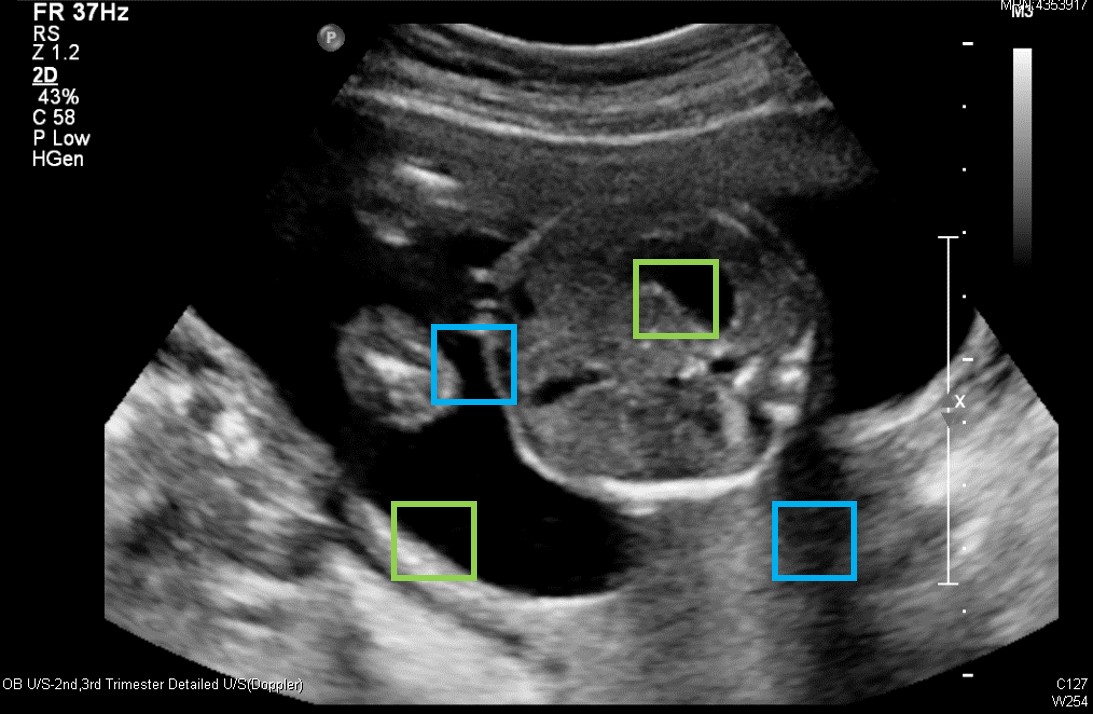
당장 위의 그림만 봐도 녹색끼리와 파란색 끼리를 딱 저만큼만 사람에게 보여줄 경우 사람조차 저것이 녹색의 경우 AF인지 SB인지 구분이 힘들고, 파란색의 경우 AF인지 SA인지 구분이 힘들다. 그러므로 normal view size의 인풋만 가지고는 애초에 구분이 힘들다는 사실을 알 수 있었다. 그래서 우리는 이 구분을 좀 더 엄밀하게 할 수 있도록, 실제 초음파 영상의 특징을 생각해 보았고, 다음과 같은 input을 추가하게 되었다.
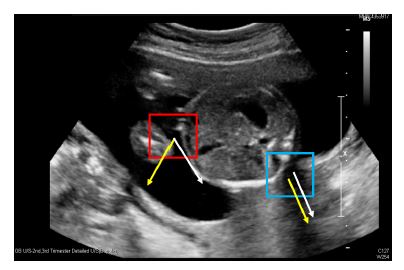
첫번째로 우리가 어떻게 전체 이미지에서 SA를 구분하는지 고찰해보면, 초음파 영상은 초음파의 물리적 성질에 의해서 SA는 반드시 초음파 진행방향으로 뼈 등의 단단한 물체 뒤에 생기게 된다. 그렇기에 각 점에서의 초음파 진행방향을 확인함으로서 구분을 할수 있다.
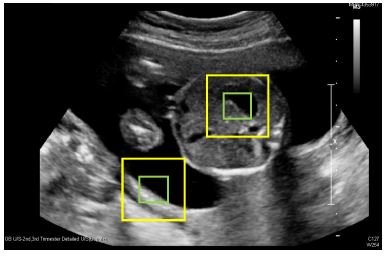
두번째로, 가장 어떤의미로 당연한 이야기지만, 위의 이미지처럼 좀 더 넓은 범위를 보게되면 구분이 가능하다. 하지만 넓은 영역을 보려고 하면 input data의 크기가 커지게 되는데, 이를 보정하기 위해 넓은 영역은 좀 더 낮은 해상도로 보았다.
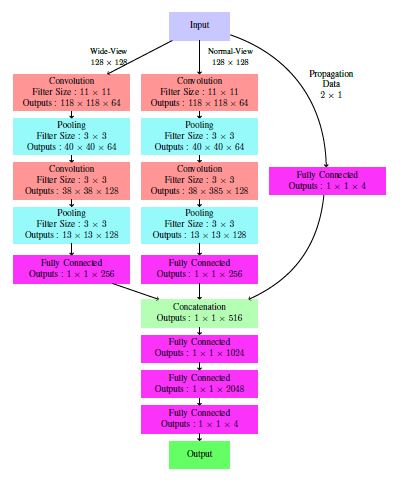
두 아이디어를 결합하여 새로 CNN을 짠 결과, 위와같은 구조가 되었다. 실제로 위의 구조를 학습시켜보니
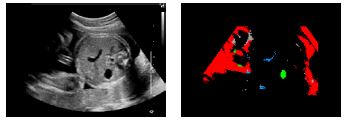
위와같은 결과를 얻을 수 있었다. 처음 시도한 normal view만을 이용한 CNN으로는 현재 주어진 의료영상 data만으로는 불가능했을 것이다.
Conclusion
이처럼 CNN등의 machine learning을 시도할 때에는, 같은 data에서도 CNN자체의 구조에 따라서 학습률이 크게 바뀐다. 그러니 좀 더 좋은, 빠른 학습을 위해선, CNN자체의 구조의 의미를 고찰하며 구조를 만들어 둘 필요가 있다.